
Streaming을 처리하기 위한 Media Type
최근에 spring ai 를 공부하고 있습니다. spring ai 는 내부적으로 webflux와 mvc 2가지 방법에 대한 가이드를 제공하는데요. 과거에 작업했던 webflux 덕분에 이해를 수월히 하고 있습니다. 공부를 하면서 알게된 재밌는 점은 LLM이 답변을 할때 한글자씩 나오는게 단순히 UX가 아니라 실제로 내부에서 stream 처리를 하기 때문이라는 점 입니다.
따라서 Spring에서도 LLM의 응답을 Flux를 통해 stream으로 전달 가능한데요.
이때 application/x-ndjson media type를 처음 보게되어 정리한 내용입니다.
@PostMapping(
"/chat",
consumes = [MediaType.APPLICATION_FORM_URLENCODED_VALUE],
produces = [MediaType.APPLICATION_NDJSON_VALUE]
)
fun getAnswer(question: String): Flux<String?> {
val prompt = Prompt.builder()
.content(question)
.build()
return chatClient.prompt(prompt)
.stream()
.content()
}
application/X-NDJSON
IANA에 등록된 공식 타입은 아니지만 현재 널리 사용되고 있는 타입입니다. ndjson-spec에서 상세스펙을 확인할 수 있으며 이름에서 보듯이 Newline delimited JSON 의 약자입니다.
사실 elasticsearch를 사용했으면 이미 본적이 있는 형태입니다 . bulk api 사용시 아래와 같은 형태로 요청을 하게 됩니다 .
POST _bulk
Content - Type: application/x-ndjson
{ "index": { "_index": "products", "_id": "1" } }
{ "name": "화이트 셔츠", "price": 29000 }
{ "index": { "_index": "products", "_id": "2" } }
{ "name": "블랙 팬츠", "price": 49000 }
과거에는 json array가 아닌데 신기하네? 라고만 생각했는데 알고보면 이런 정해진 방식으로 처리를 하고 있었습니다. 그렇다면 json array를 사용하지 않고 ndjson 을 사용하는 이유가
무엇일까요?
VS. Json Array
elasticsearch bulk api의 예시는 간단한 형태지만, 저런 데이터가 수천, 수만건이라고 가정을 해보면 좋습니다. application 내부에서 객체를 판단하기 위해선 [ ] 로 시작되는 데이터를
전부 읽어야 하고 그 데이터를 메모리에 로드해야 합니다. 이때 특정 순서의 데이터가 문제가 발생하면 전체가 실패하는 상황도 발생합니다.
[
{
"id": 1,
"name": "상품-00001",
"category": "가전",
"price": 199000,
"tags": [
"세일",
"신상품"
],
"createdAt": "2025-10-04T09:00:00Z"
},
{
"id": 2,
"name": "상품-00002",
"category": "패션",
"price": 59000,
"tags": [
"베스트셀러"
],
"createdAt": "2025-10-04T09:05:00Z"
},
...
...
...
...
{
"id": 10000,
"name": "상품-10000",
"category": "식품",
"price": 12900,
"tags": [
"할인",
"추천"
],
"createdAt": "2025-10-04T09:10:00Z"
}
]
// 만약 중간에 데이터가 잘못되었다면?
// 데이터의 양이 너무 많아 메모리에 적재시 문제가 생긴다면?
위와 같은 문제를 해결하기 위해 라인별로 데이터를 처리하는 application/x-ndjson 를 사용하며 기존의 json 파서를 그대로 사용하면서 유연하게 대용량 처리를 가능하게 합니다.
With Spring
그렇다면 spring 에선 어떻게 이러한 타입을 처리하고 있을까요?? 기본 설정인 경우 내부적으로 메시지를 jackson으로 처리합니다.
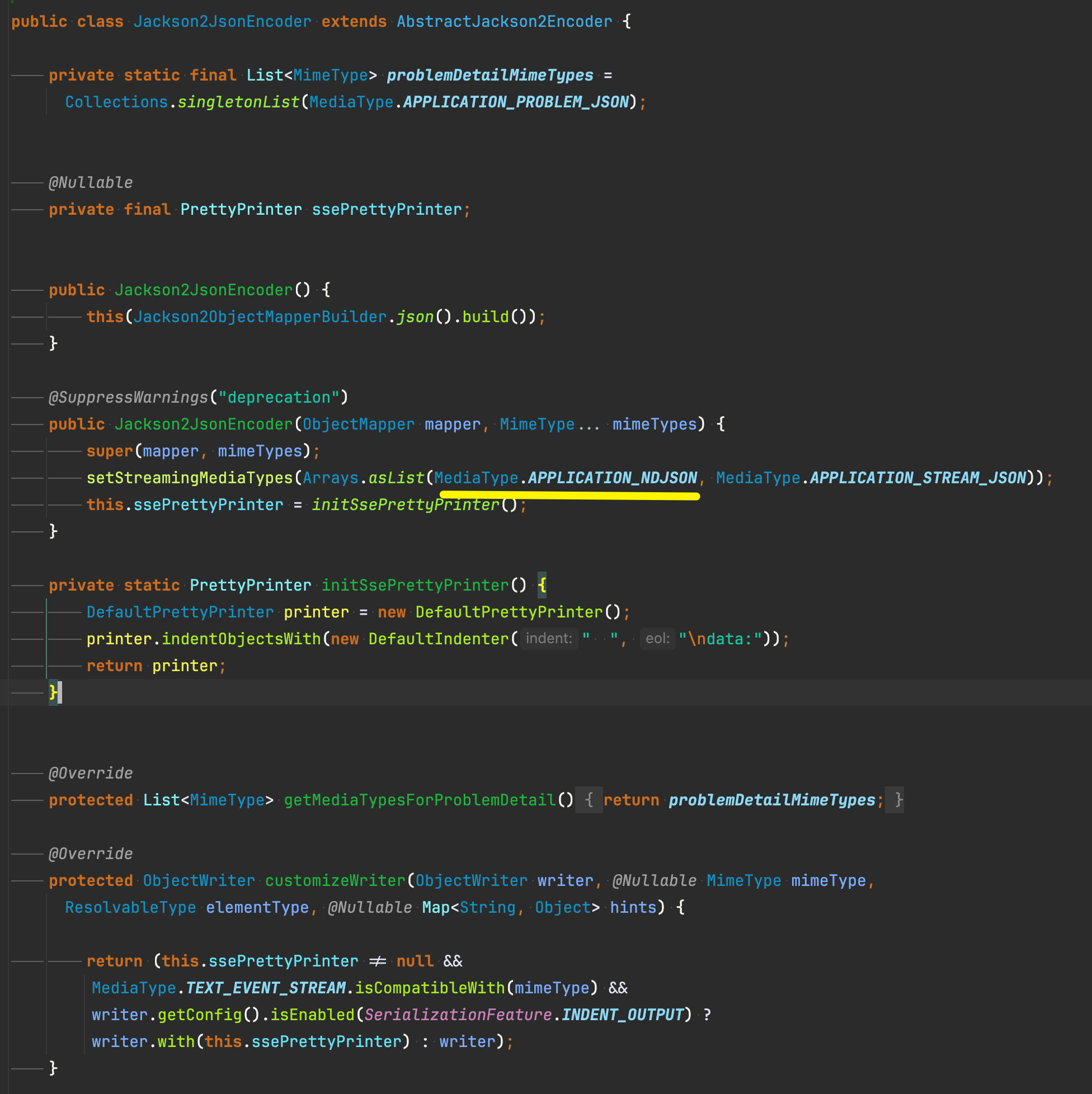
직렬화하는 jackson encoder를 보면 내부에서 streaming 처리를 위한 타입으로 application/ndjson에 관한 정보를 등록하고 있습니다.
메서드에 deprecation 이 보이지만 APPLICATION_STREAM_JSON 을 사용하지 않는다는 의미이며 실제 호출을 해보면 해당 생성자는 정상적으로 사용되고 있습니다.
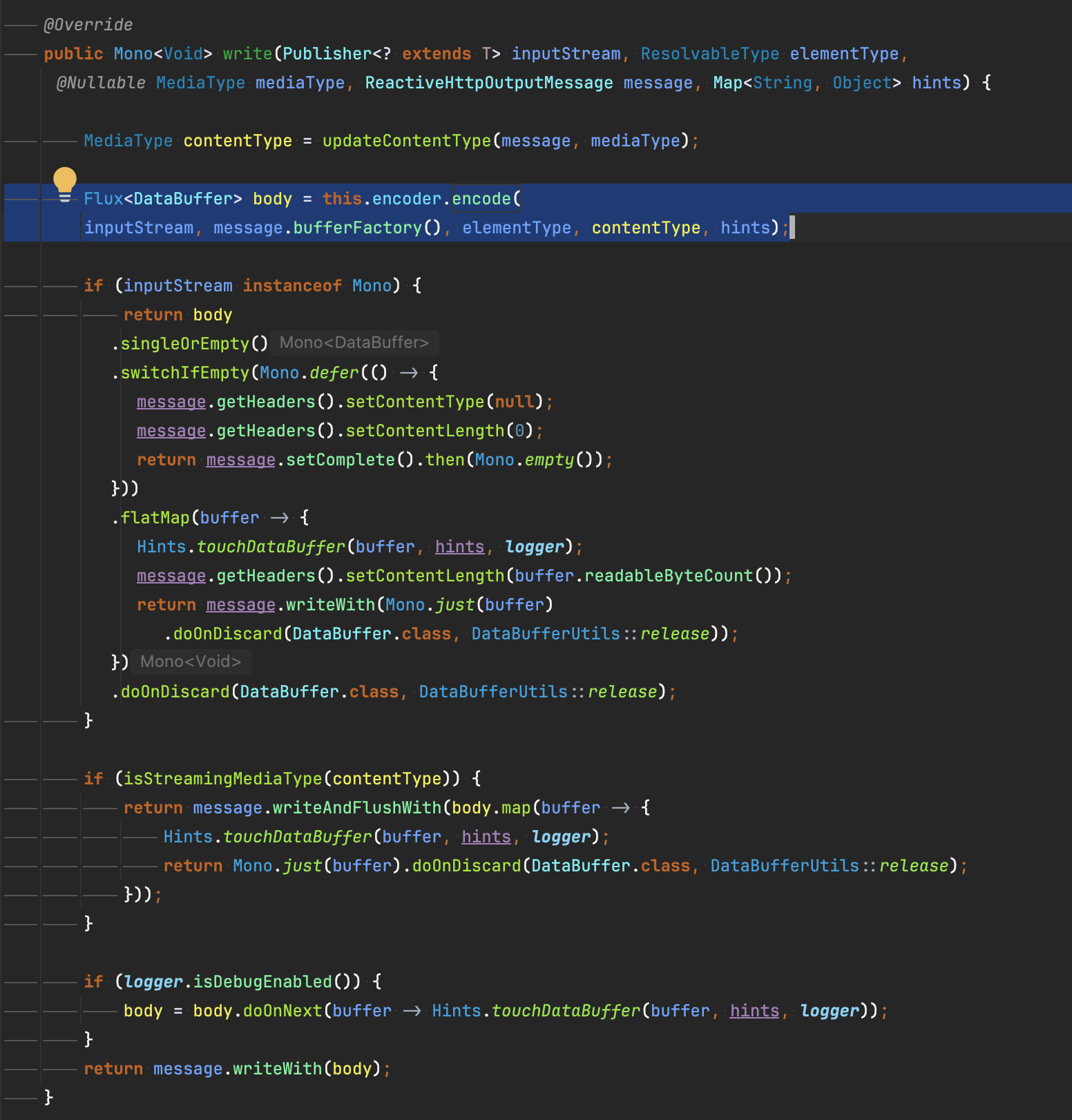
이후 실질적으로 데이터를 생성하는 부분은 EncoderHttpMessageWriter.write 에서 확인 가능합니다. encode 메서드를 호출하여 데이터를(response body)를 직렬화 하는걸 볼 수 있습니다.
objectMapper의 구현체를 설정하지 않았다면 기본적으로 jackson을 사용하며 내부적으로 streaming에 대한 처리 하는 것을 확인할 수 있습니다.
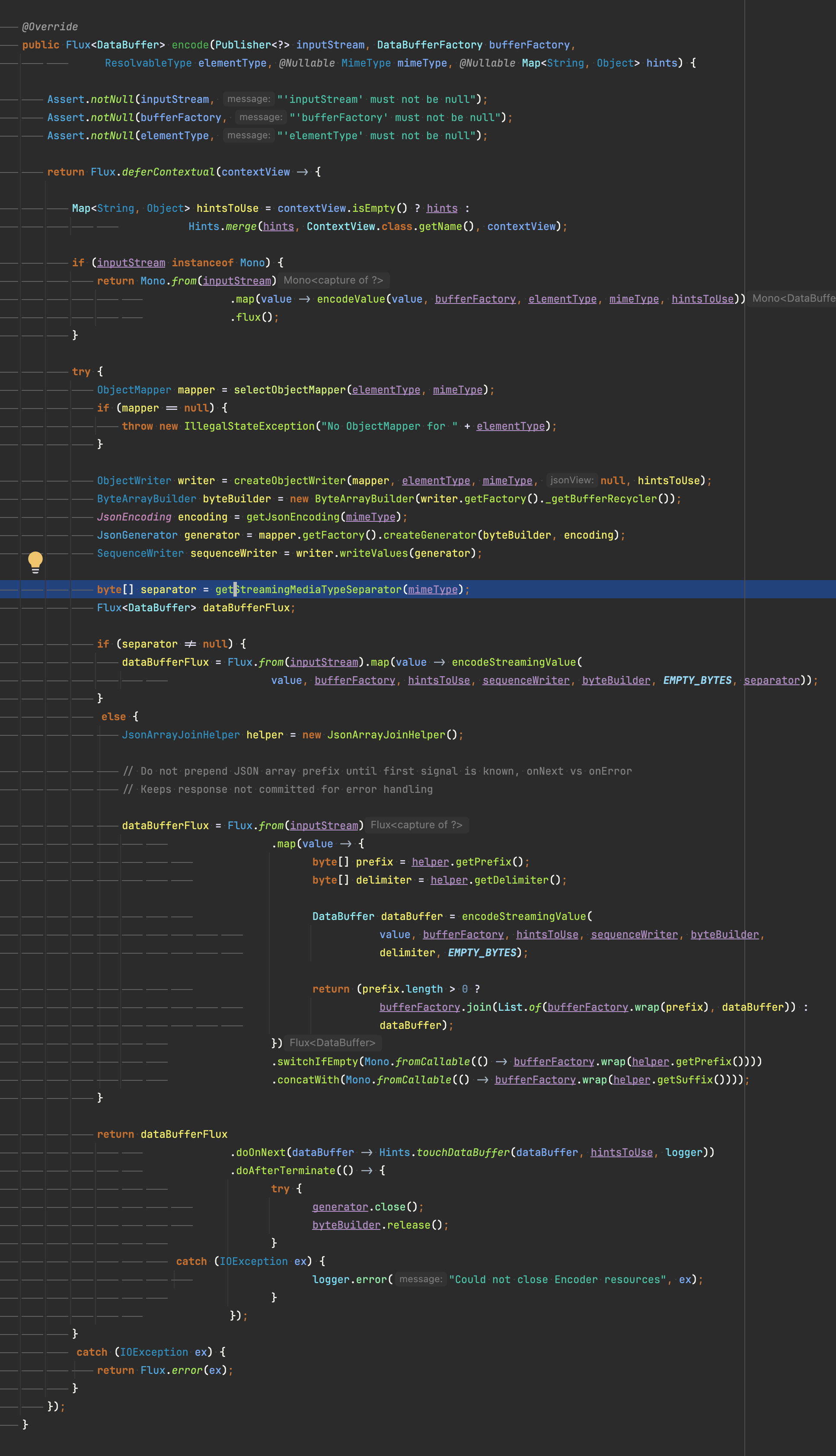
\n을 seperator로 하여 반환하는 모습

이러한 과정을 통해 아래와 같이 LLM이 stream으로 전달하는 데이터를 전달받을 수 있습니다.
{
"answer": "대한"
}
{
"answer": "민국"
}
{
"answer": "의"
}
{
"answer": " 수도"
}
{
"answer": "는"
}
{
"answer": " 서울"
}
{
"answer": "입니다"
}
{
"answer": "."
}
MVC 에서 ndjson 사용하기
Spring MVC에서도 ndjson 방식의 streaming 처리가 가능합니다. Streamingresponsebody를 사용하거나 또는 추상화 되어있는 ResponseBodyEmitter를 사용하면
편리합니다.
@GetMapping(
"/chat",
consumes = [MediaType.APPLICATION_FORM_URLENCODED_VALUE],
produces = [MediaType.TEXT_EVENT_STREAM_VALUE]
)
fun stream(question: String): ResponseEntity<ResponseBodyEmitter> {
val emitter = ResponseBodyEmitter()
val executor = Executors.newSingleThreadExecutor() // ... (1)
executor.execute {
for (i in 0..100000000) {
val jsonLine = mapper.writeValueAsString(mapOf("key" to i)) + "\n"
emitter.send(jsonLine)
}
emitter.complete() // ...(2)
}
return ResponseEntity.ok() // ... (3)
// NDJSON을 위한 미디어 타입
.contentType(MediaType.parseMediaType("application/x-ndjson"))
.body(emitter)
}
- (1): 바동기적으로 stream 처리를 위해 새로운 쓰레드를 만들어 처리합니다.
- (2): 요청이 완료되면 complete 를 통해 chunk: 0 처리를 합니다.
- (3): ResponseBodyEmitter를 반환합니다.
번외
streaming을 하기 위해 반드시 application/x-ndjson을 사용하는 것은 아니다.
application/x-ndjson을 통해 streaming을 처리하는 예제를 설명하지만 Flux<String> 이나 application/json 으로 한다하여도 streaming으로 작동합니다.
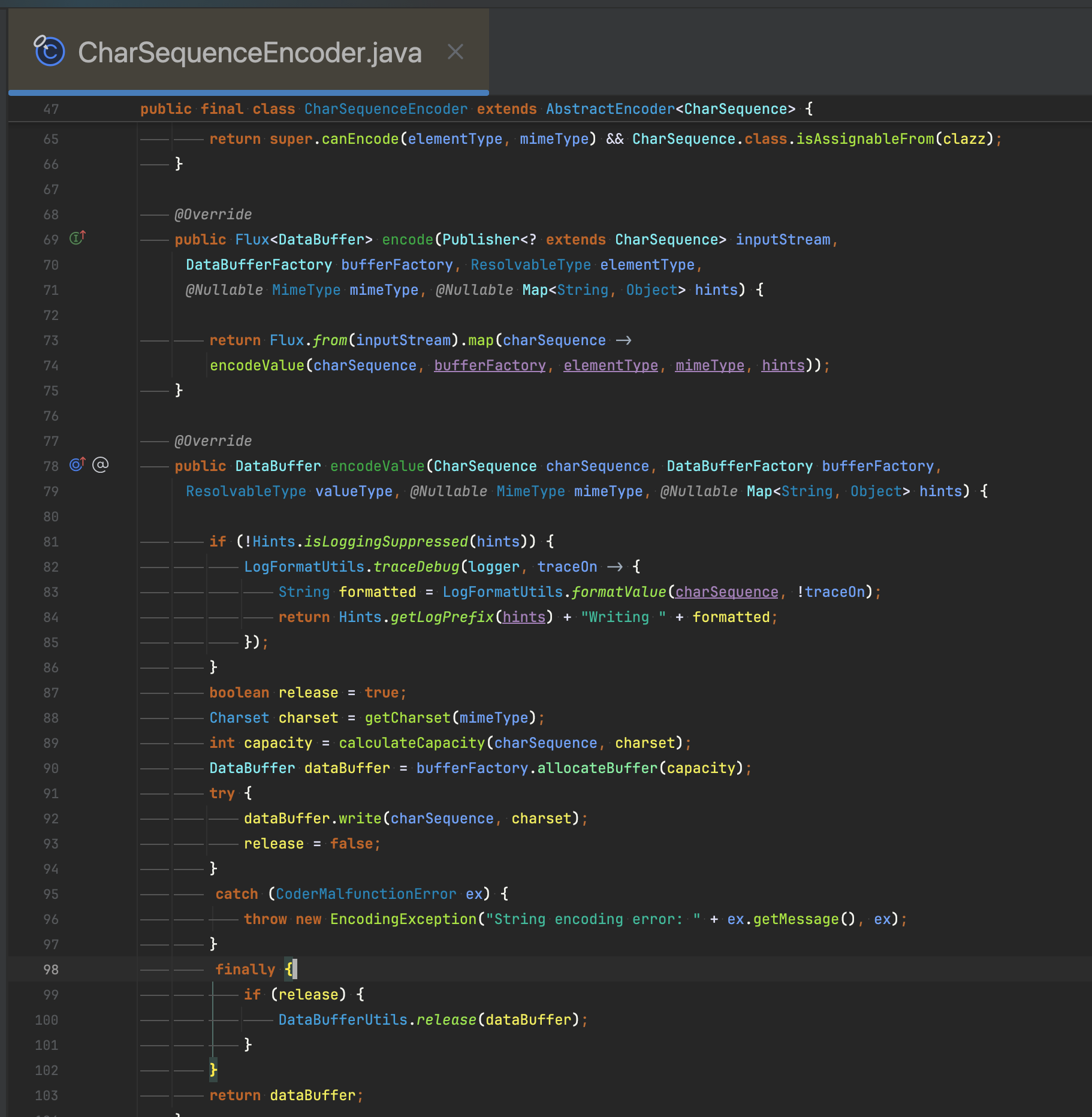
Flux<String>사용시 encoder가 CharSequenceEncoder설정되며 내부적으로 buffer를 두어 stream 처리하는 코드를 확인할 수 있습니다. 다만 주의할 점은 이때의 데이터
streaming단위는 http의 chunk 방식에 따라 나뉘게 됩니다.
예를들어 아래와 같은 형태의 데이터를 서버에서 내려준다고 가정하면
[
{
"id": 1,
"name": "상품-00001"
},
{
"id": 2,
"name": "상품-00002"
},
{
"id": 3,
"name": "상품-00003"
}
]
극단적인 예시지만 아래와 같이 쪼개질 수 있습니다.
HTTP/1.1 200 OK
Content-Type: application/json
Transfer-Encoding: chunked
7 # 첫 번째 청크 크기(16진수, 7바이트)
[ # 데이터(아직 JSON이 시작만 되고 덜 옴)
{
"id": 1
10 # 두 번째 청크 크기(16진수, 16바이트)
, "name": "상품-00001"
}, # JSON 중간에 끊겨버림
0E # 세 번째 청크 크기(16진수, 14바이트)
{
"id": 2, "na
0D # 네 번째 청크 크기(16진수, 13바이트)
me":"상품-00002"},
15 # 다섯 번째 청크 크기(16진수, 21바이트)
{
"id": 3, "name": "상품-00003"}
]
0 # 마지막 청크 (0 = 끝)
stream으로 전송되지만, chunk 단위가 JSON 같은 논리적 단위가 아닙니다. 클라이언트는 chunk를 그대로 처리할 수 없고, 모든 청크를 이어붙여 원본 문자열을 복원한 뒤 JSON 파싱을 해야 합니다. 따라서 네트워크 레벨에선 streaming이지만, 어플리케이션 레벨(JSON 파싱)에서는 결과를 다 모으기 전까지는 사용할 수 없습니다.
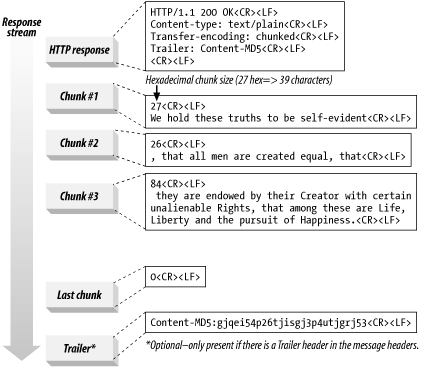
Transfer-Encoding: chunked 는 response header에 존재하며 청크로 데이터를 내려준다는 의미입니다. 과거에는 content-length 를 사용했으나, 페이지가 아닌 데이터를
내려주는 형태에서 예측이 어려워지면서 chunk 단위로 요청을 받을 수 있도록 하고 있습니다. 이외에 자세한
내용은 rfc 문서에서 확인 가능합니다.
- 참고) 좋은 설명 HTTP 프로토콜 Transfer-Encoding 헤더
client는 buffer를 통해 chunk 를 관리한다.
분명 1번에서 application/json이어도 postman과 같은 http 요청 툴을 이용해 streaming api 를 호출해보면 모든 결과가 한번에 나오는 것 처럼 보입니다.
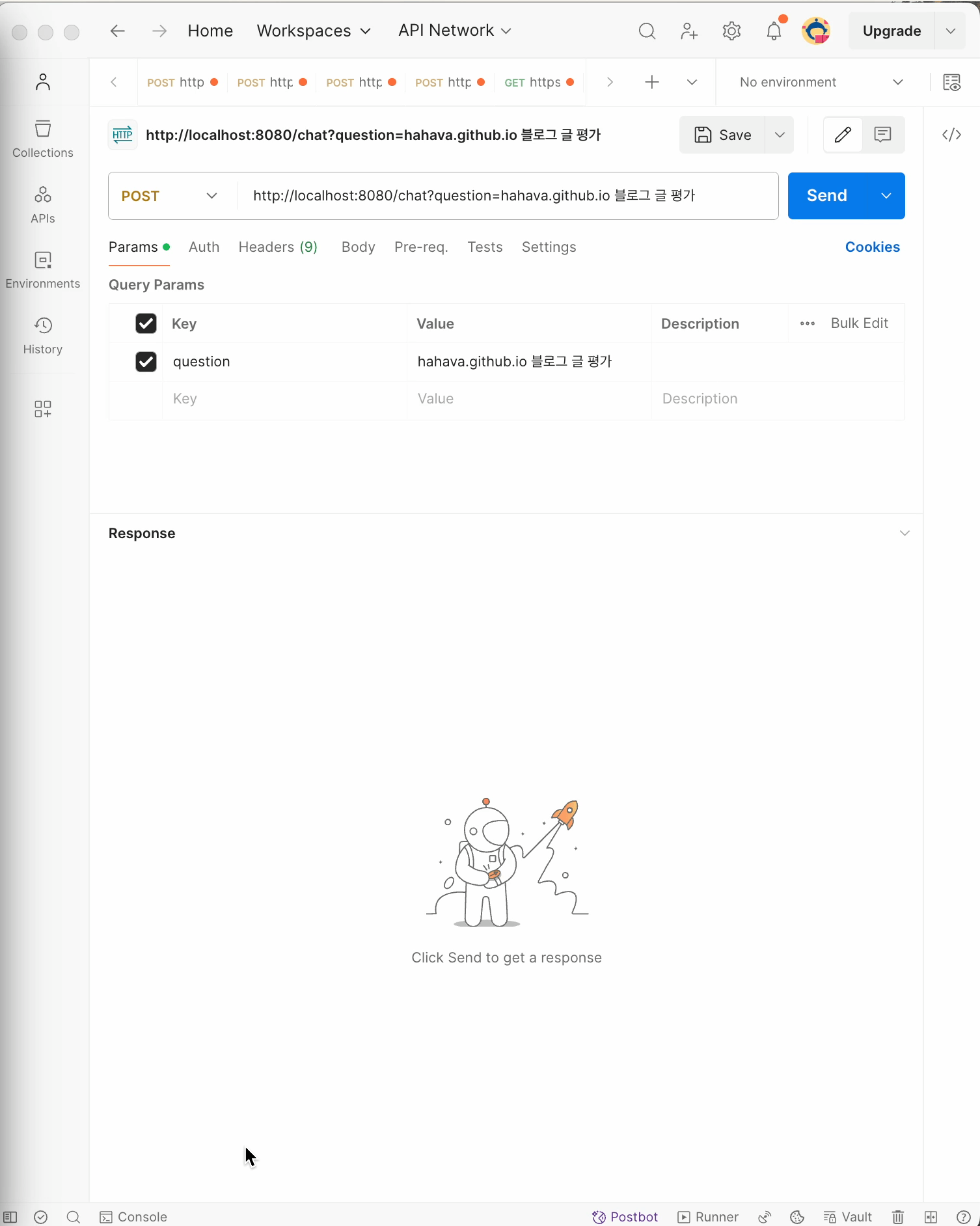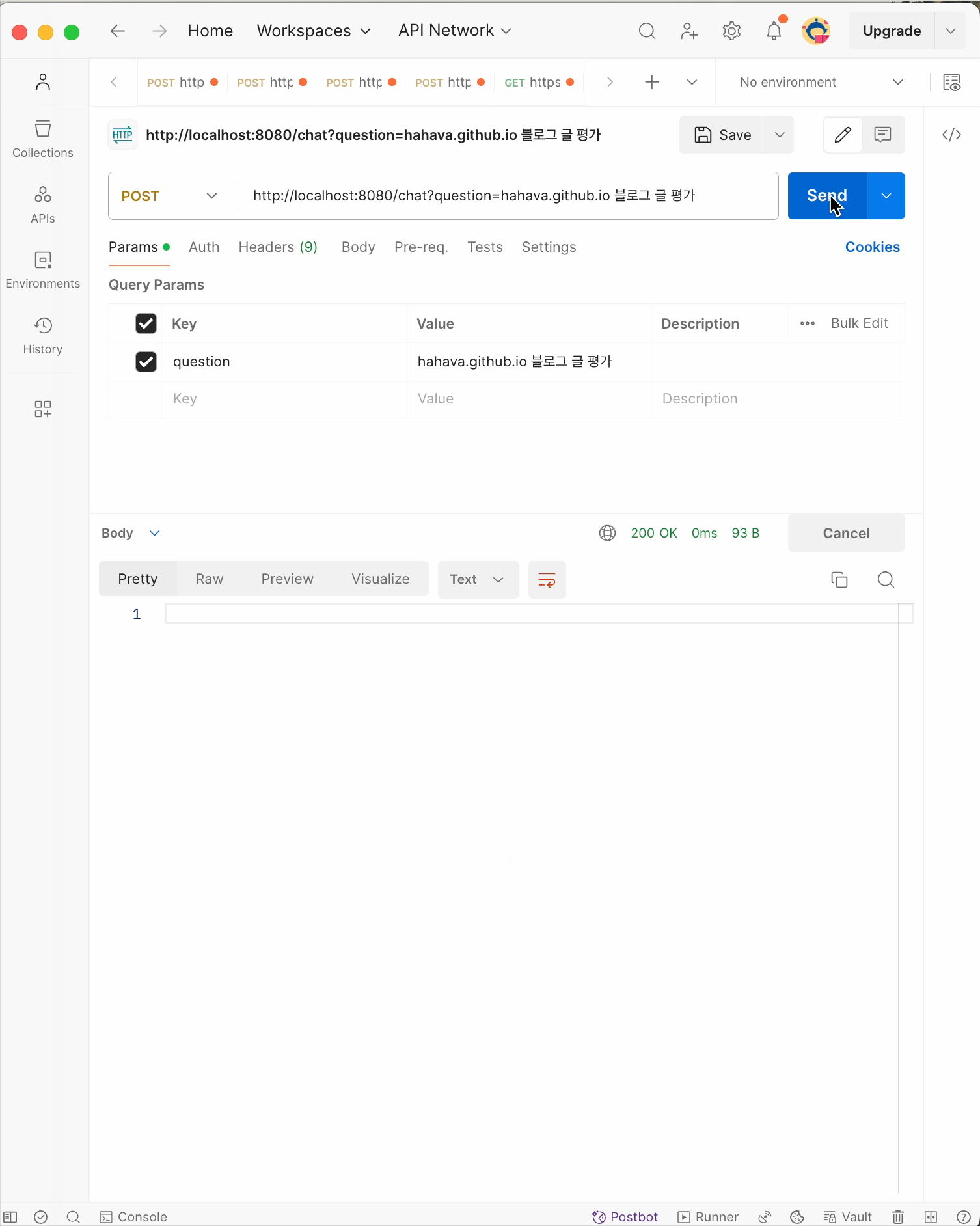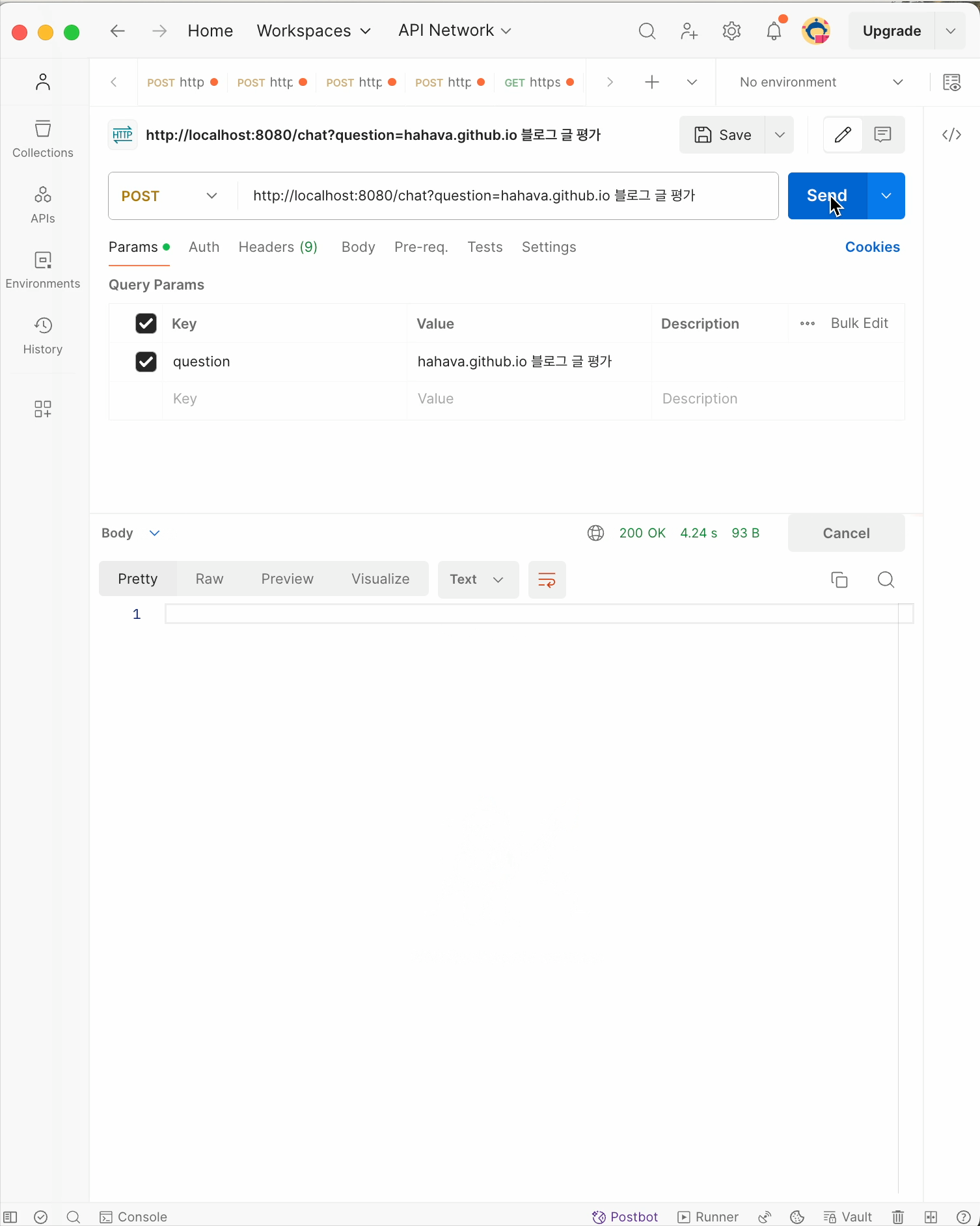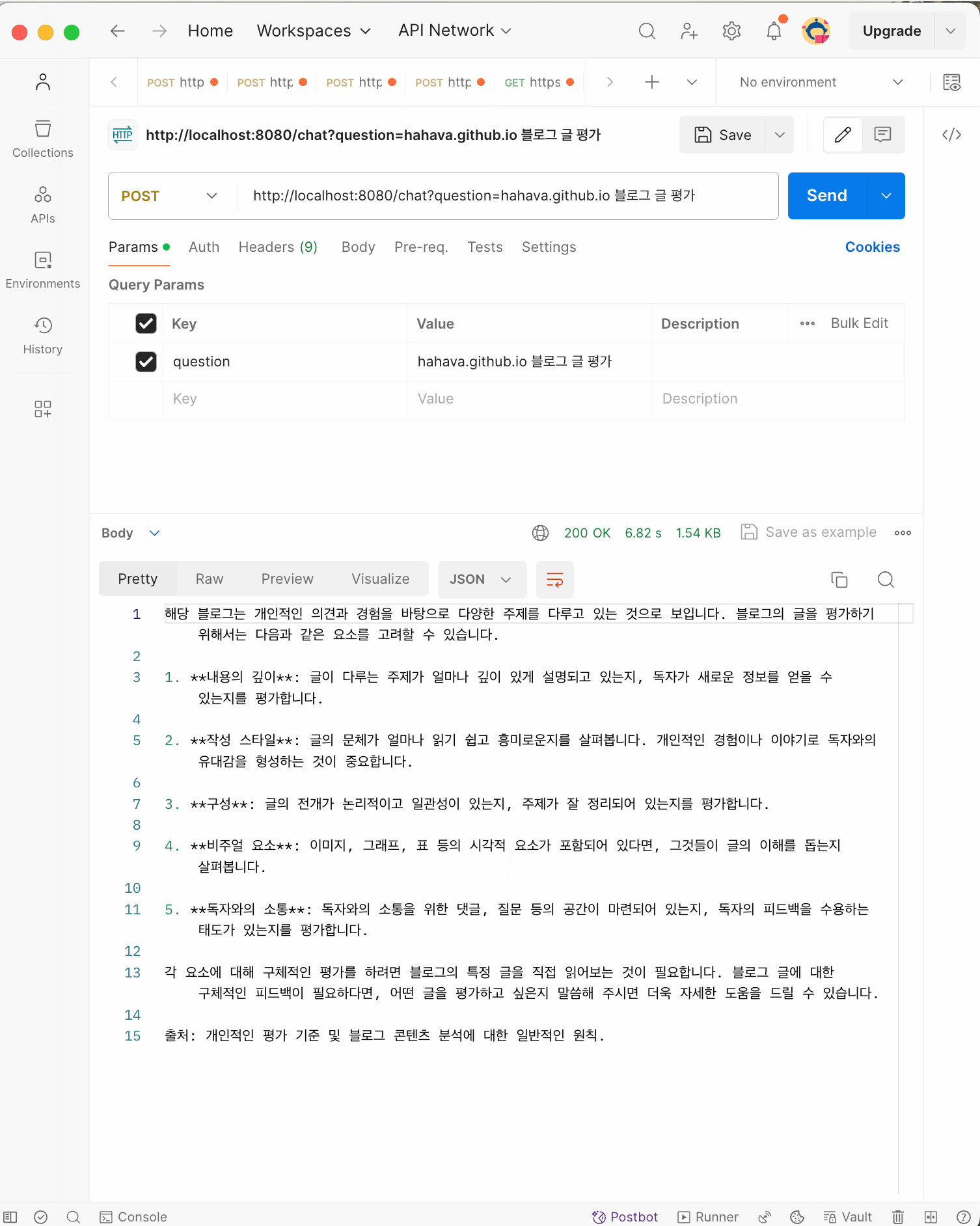
사실 이러한 내용은 client side 에서 chunk 으로 된 응답은 buffer에 담아두기 때문에 그렇습니다. curl 로 하여 no-buffer (-N 옵션을 추가하여)로 호출해보면 청크단위로 출력하는 것을 확인할 수 있습니다.
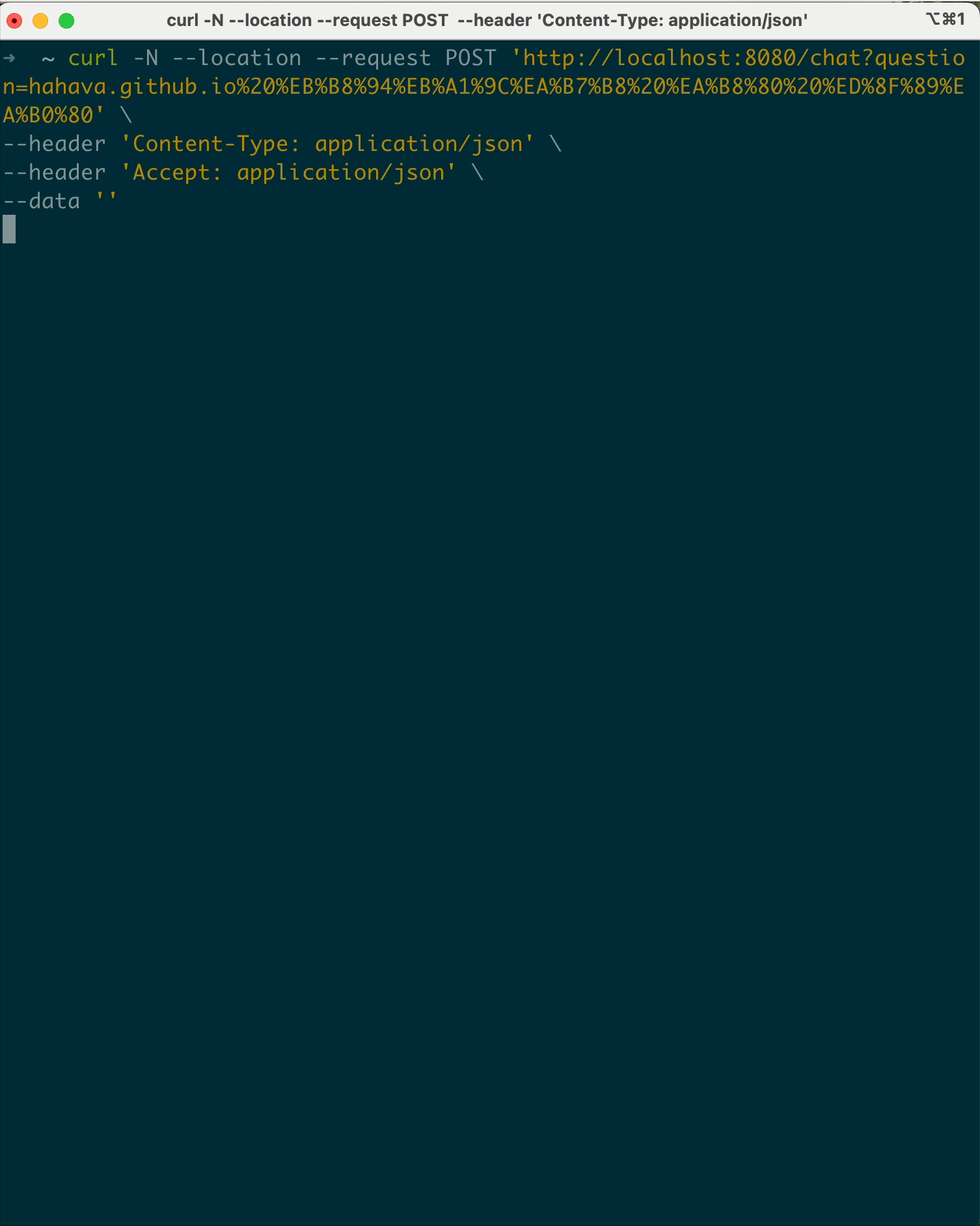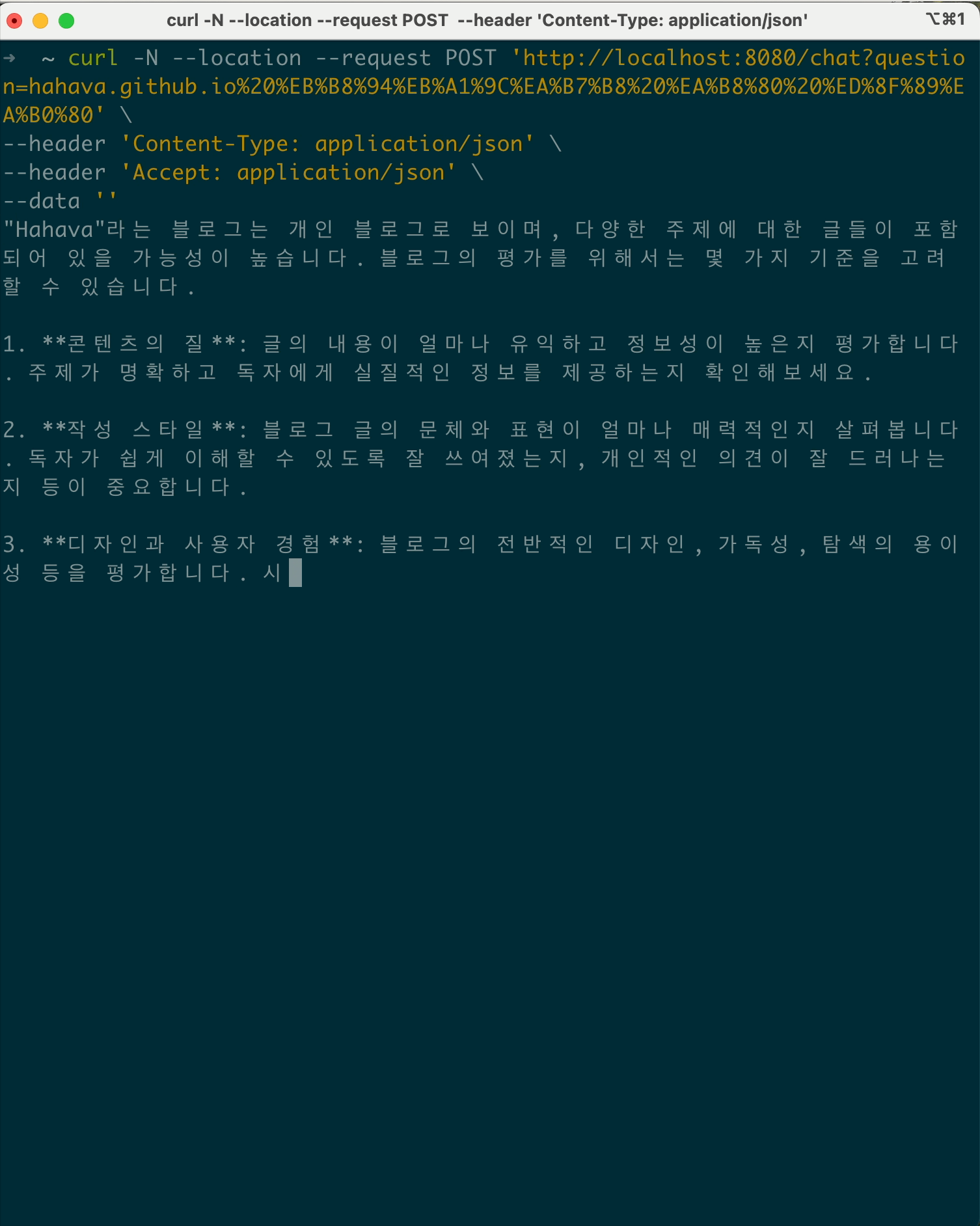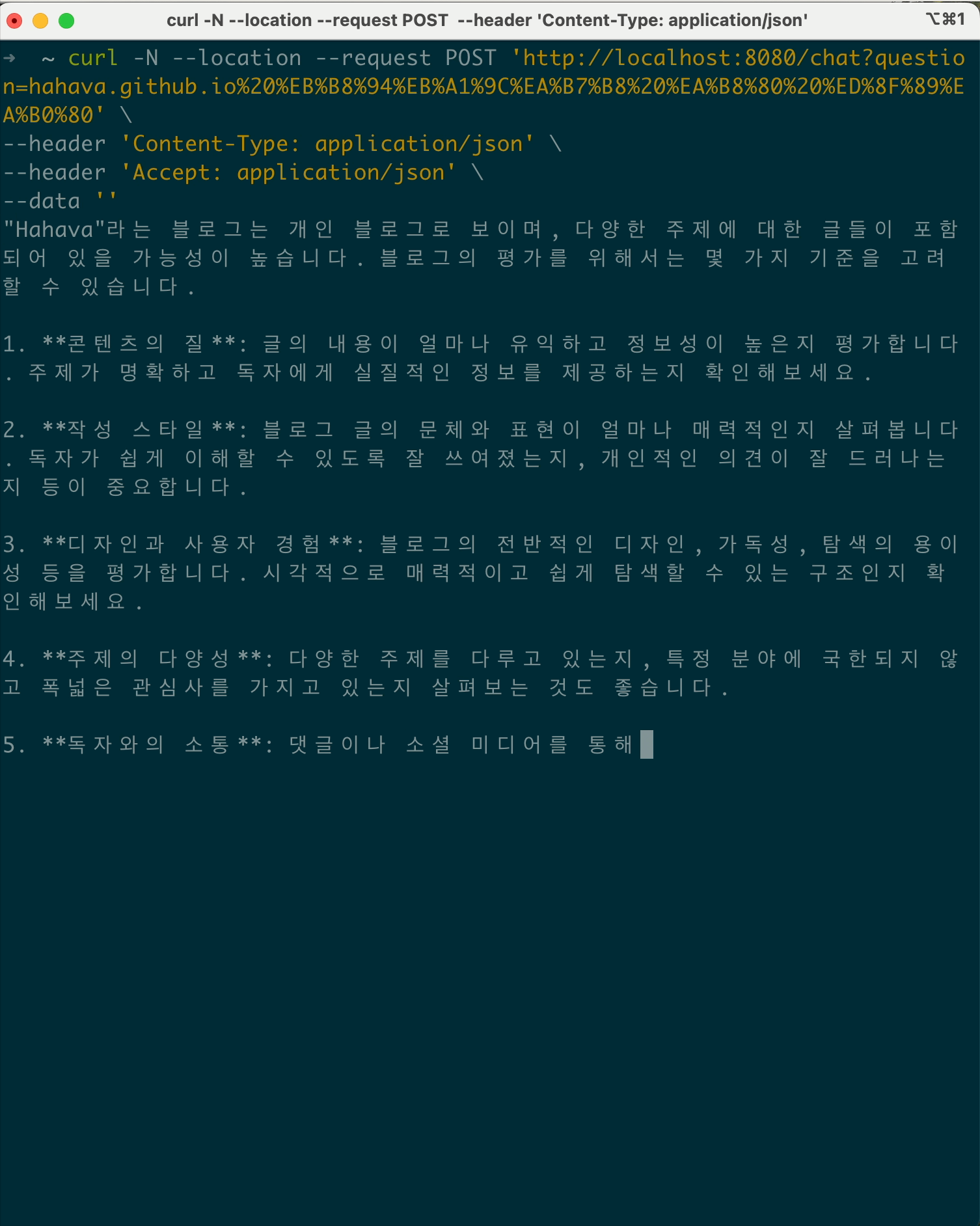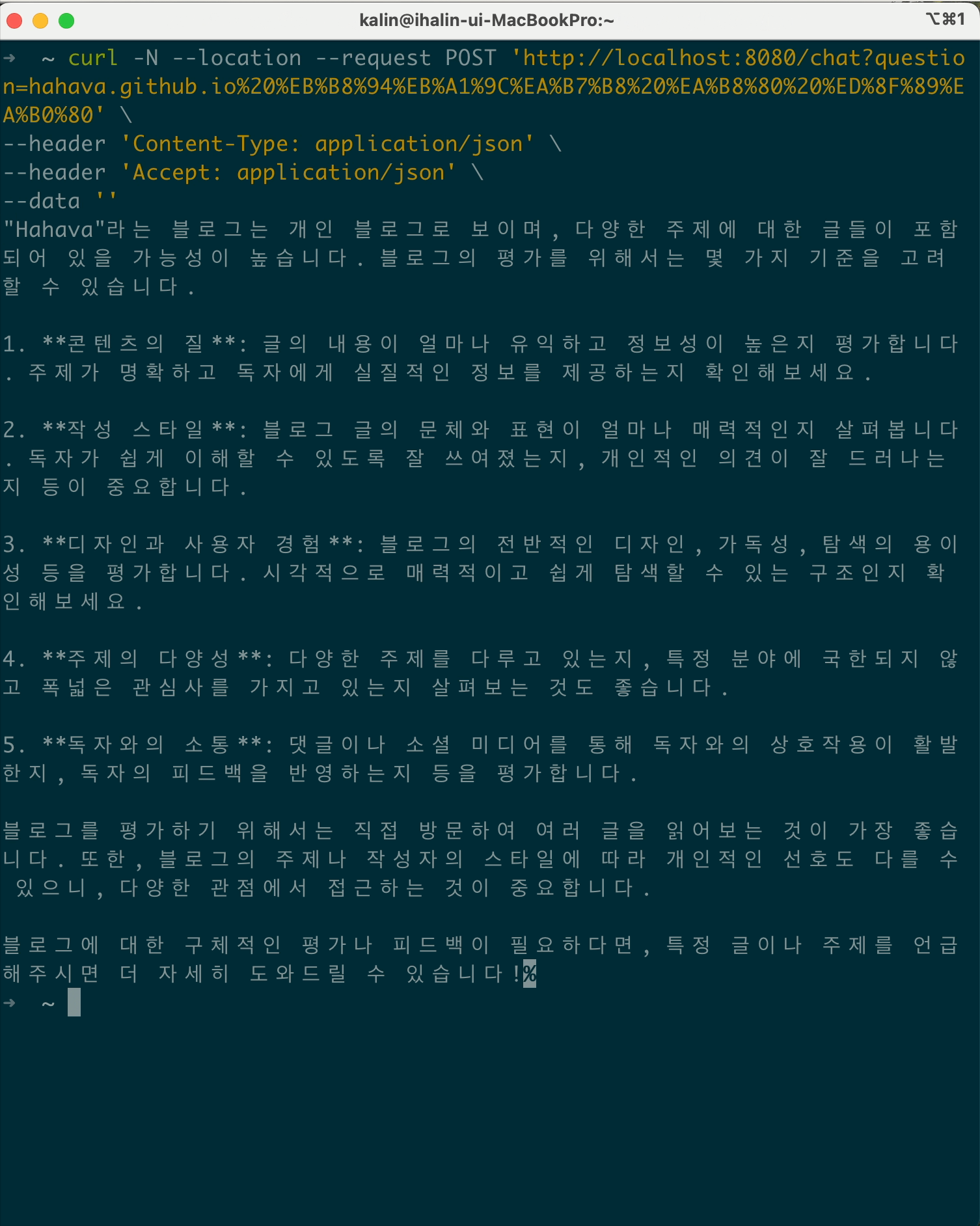
postman에도 issue로 등록되어 있지만 현재 처리는 안된 모습…
결론
- spring webflux 에선 mediaType에 따라 http 응답 방식을 반환하는 내부 동작이 달라진다.
- streaming을 사용한다면
application/x-ndjson을 이용해서 진정한 의미의 streaming 처리를 해보자. - streaming 처리시 client느 내부적으로 buffer를 이용하고 있다
댓글남기기